Advanced Radical-Based Kanji Look-Up in a Japanese-English
Hyperdictionary
Vadim V. Smolensky,
June 6, 1996
Abstract
A novel approach to kanji look-up in a Japanese-English hyperdictionary is suggested that is based on an original classification of kanji elements, properly organized user-friendly menu and three modes of search.
Recently, a number of attempts have been made to break the monopoly of the conventional 214-radical kanji look-up approach. Alternative systems are suggested in new kanji dictionaries. M. Spahn and W. Hadamitzky [1] reduce the number of radicals down to 79. J. Halpern [2] gives up the radical-based look-up and replaces it by splitting the character and counting strokes in its parts. Together with additional methods of locating kanji, these systems are meant to make the dictionaries convenient and easy to use.
Hyper-media computer implementation, by its very nature, provides new possibilities for developing kanji look-up tools, much more powerful than those developed for linear dictionaries. One such approach is the input of kanji in an explicit form, for example using a pen-like device, and processing the picture by means of logic programming [3]. This way seems convenient, especially for naive learners who cannot yet recognize the internal structure of kanji. Besides, it could be a great help in forming kanji writing skills.
However, an advanced learner would likely prefer radical-based
look-up methods. These methods can also be strongly modified in
computer implementation. In particular, a properly organized menu can
support not less but more than 214 radicals, allowing the user to
specify kanji without counting strokes. The spatial information,
i.e. mutual arrangement of radicals, is not important (unlike with the
pen-based input methods) because a full set of radicals normally
corresponds to only one character. For example, radicals "cloth",
"sun" and "eye" uniquely determine the character 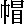 ("hat"):
("hat"):

("F" stands for "full definition").
In few cases, a full set of radicals corresponds to more than one kanji:
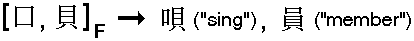
This means that the look-up process is split into two steps: the user gets several characters and selects the required one.
Furthermore, if we do not insist on one-step look-up, it turns out that in most cases we need not specify all the radicals; some of them can be left unspecified:


("P" stands for "partial definition").
In these examples, we get as many as five characters because
 is a very frequently used radical. Normally, we
would get a smaller number of characters, often just one:
is a very frequently used radical. Normally, we
would get a smaller number of characters, often just one:
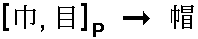
Some characters have such complicated or odd shapes that even an
experienced learner can hardly recognize all of their elements. These
characters can be united into a group of "difficult kanji." This group
will contain about 200-300 characters, such as  ("imperial seal"),
("imperial seal"),  ("sack"),
("sack"),  ("melancholy"),
("melancholy"),  ("hare"). As it is much less
than the total set of kanji, specifying just one radical or just the
stroke number and then searching exclusively within the set of
"difficult kanji" would be enough to get the required character.
("hare"). As it is much less
than the total set of kanji, specifying just one radical or just the
stroke number and then searching exclusively within the set of
"difficult kanji" would be enough to get the required character.
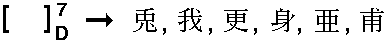
Specifying the stroke number (along with the element) remains a
powerful tool that can be used alternatively. In many cases, this is
more convenient than specifying all the radicals which may be unique
or difficult to recognize. For example, the inner part of
("drawing") is unique and can only be decomposed
to four one-stroke elements. But it is easier just to count them:
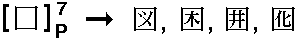
On the other hand, we would obtain a better result specifying two elements:
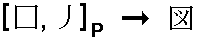
Sometimes, the learner knows the kanji reading beforehand. Readings also can be used to narrow down the obtained set of kanji:

As for Japanese readings, they normally can determine one or few kanji without any radicals specified:
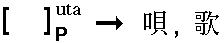
The same is true for meanings:
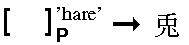
Thus, we have three modes of kanji search (search for fully specified characters, for partially specified characters and for difficult characters, designated by F, P and D respectively) and three auxiliary ways of specifying kanji (by stroke number, reading and meaning). Radicals for selection are presented in a specially developed table-like clickable menu (Figure 1). The total number of radicals is approximately 500; all of these have been selected on the basis of a thorough and comprehensive classification of kanji elements, which is quite original and independent of any existing classification.
Of prime importance is the layout of the table. Radicals are grouped in ten columns according to the stroke number: the extreme left column is for single-stroke radicals, the extreme right one is for those written by ten strokes or more. The menu is scrollable up and down because the screen accommodates only about 1/2 of the total number of radicals (and about 1/3 of the table height; this is because some columns are longer than others). However, the most common radicals are concentrated in the top so that in most cases scrolling is not necessary. The lower part of the table contains the most esoteric and rarely used elements. Particular attention has been given to placing similar radicals closely to each other, both in columns and in rows, sometimes forming entire areas of homomorphous elements, in order to make looking for a radical as convenient as possible.
For the same purpose, the option of highlighting position-oriented
radicals is provided. Most radicals can appear in a certain position
(left, right, top, bottom, enclosing); the others form the group of
"neutral" radicals. For example, 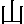 can appear at
the left and at the top;
can appear at
the left and at the top; 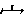 is always at the top;
is always at the top;
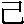 is a typically neutral radical. The groups
overlap but not significantly. Therefore, highlighting a group would
considerably simplify the search of the required element. Highlighting
the "top" radicals when they are bold and all the others are pale, is
shown in Figure 2. A similar
option can be provided to highlight visually similar radicals, for it
is not possible to place all of them closely to each other.
is a typically neutral radical. The groups
overlap but not significantly. Therefore, highlighting a group would
considerably simplify the search of the required element. Highlighting
the "top" radicals when they are bold and all the others are pale, is
shown in Figure 2. A similar
option can be provided to highlight visually similar radicals, for it
is not possible to place all of them closely to each other.
The look-up process runs as follows. The user analyzes the kanji, selects the recognized radical(s) by mouse and/or enters the number of strokes (or reading, or meaning). Then (s)he presses one of the three buttons F, P or D, corresponding to the selected search mode and obtains either the desired dictionary entry or a set of characters for further selection if the entered data was not enough for full identification.
In order to simplify counting strokes, extra options are provided. When the user is not sure about the exact number of strokes, (s)he can press the "±1" or "±2" button and search within the respective range. Approximate count is also possible, by pressing buttons ">10" and ">20". Another helpful option is displaying the close-ups of complicated and indistinct radicals, as well as demonstrating samples of kanji that contain a given radical. These functions are available through pop-up menus provided for most elements in the table.
As mentioned above, the method is primarily intended for intermediate and advanced learners. However, due to its simplicity and clear structure of the menu, it can be offered to beginners as well, especially for those who want to make good and rapid progress in written Japanese. The described hyperdictionary is now being developed as a part of the courseware "Kanjichain" based on the original conception of phonetic grouping and plot mnemonics [4]. It is going to be provided with a detailed manual, powerful help system and special mode for beginners designed to acquaint them with the basic kanji radicals. On the other hand, it will be possible to use the hyperdictionary as an independent software, linking it with other programs.
Apparently, the idea can also be applied to Chinese and Korean languages, as they basically use the same characters. This probably will require some changes in the structure of the menu.
References
M. Spahn, W. Hadamitzky, The Kanji Dictionary, Charles E.Tuttle Company, 1996.
J. Halpern (Editor in Chief), New Japanese-English Character Dictionary, Kenkyusha, 1990.
H. Abramson, S. Bhalla, K. Christianson, J. Goodwin, J. Goodwin, L. Schmitt, J. Saraille, The Logic of Kanji Lookup in a Japanese-English Hyperdictionary, ALLC-ACH`96.
V. Smolensky, The Chain Method of Studying Japanese Characters, preprint, 1995.
Published in Proceedings of the Seventeenth International Conference on Computer Processing of Oriental Languages (ICCPOL'97), Hong Kong Baptist University Press.